
今回はPower AppsではなくAzureの話です。参考にするリポジトリはこちらです。
Azure-Samples/azure-search-openai-demo
Azure OpenAI とCognitive Search を利用してBLOBにアップロードした社内文書をチャット形式で検索できる WebアプリをGitHub からデプロイします。
目次
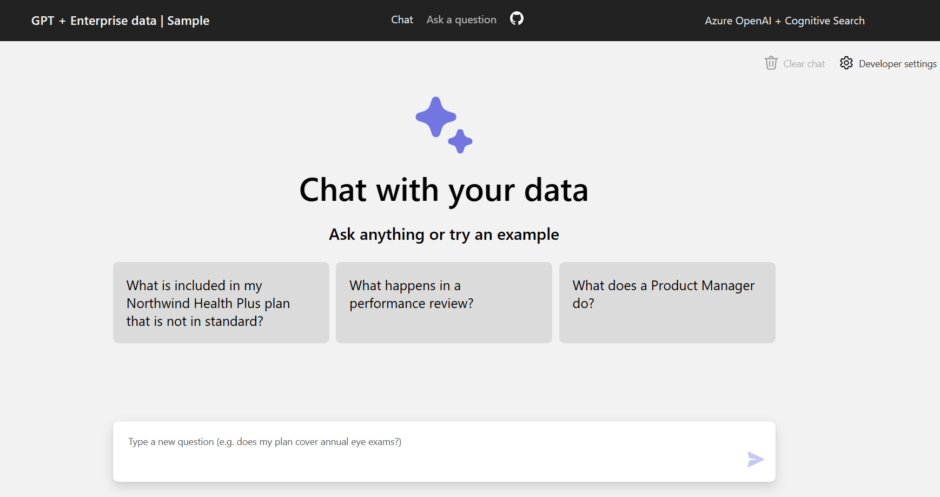
完成形のアプリ
完成するアプリの様子です。このように動きます。
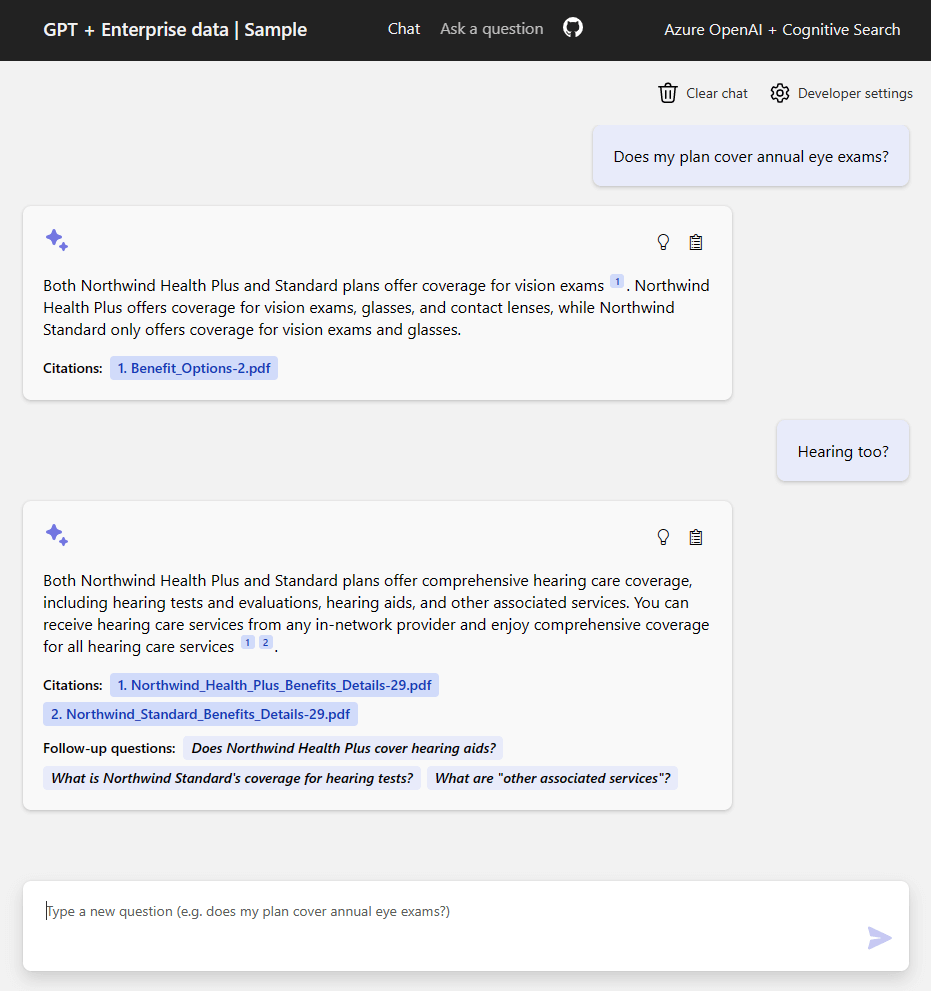
このサービスはWeb Apps としてデプロイされます。
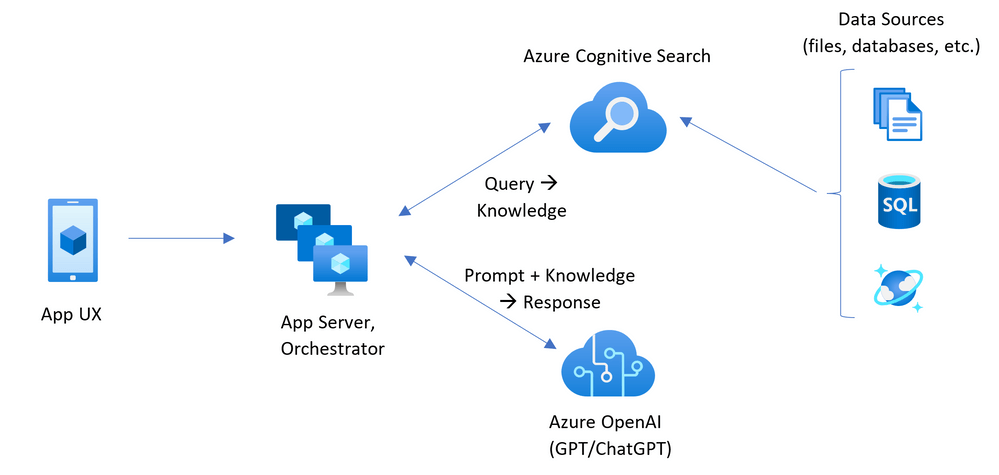
Azure コスト
Azure で発生するコストは以下のとおりです。
- Azure App Service: Basic Tier with 1 CPU core, 1.75 GB RAM. Pricing per hour. Pricing
- Azure OpenAI: Standard tier, ChatGPT and Ada models. Pricing per 1K tokens used, and at least 1K tokens are used per question. Pricing
- Form Recognizer: SO (Standard) tier using pre-built layout. Pricing per document page, sample documents have 261 pages total. Pricing
- Azure Cognitive Search: Standard tier, 1 replica, free level of semantic search. Pricing per hour.Pricing
- Azure Blob Storage: Standard tier with ZRS (Zone-redundant storage). Pricing per storage and read operations. Pricing
- Azure Monitor: Pay-as-you-go tier. Costs based on data ingested. Pricing
認証の追加
デプロイしたアプリは標準ではPublicに公開されてしまいます。Microsoft Entra ID の認証はご自身で設定する必要があります。
チュートリアル – Azure App Service の Web アプリにアプリの認証を追加する – Azure App Service | Microsoft Learn
デプロイ方法
それではこちらのリポジトリをデプロイしましょう。
GitHub からのデプロイ
GitHub Codespaces からデプロイします。以下のリンクからGitHubのリポジトリに移り、GitHub Codespaces のボタンを探し、クリックしてデプロイします。
GitHub – Azure-Samples/azure-search-openai-demo
設定
Codespaceの設定は以下のようにしました。
しばらくLoading画面が表示されます。

VS Code の形式で開かれる
CodespaceがみなれたVisual Studio Code の形式で開かれます。
まず、自分のリソースにアクセスするためAzure にログインします。
azd auth login --use-device-codeデバイスコードが生成されますのでコピーしておきます。
一度エンターキーを押します。すると、別のタブでログイン ウイザードが開きます。
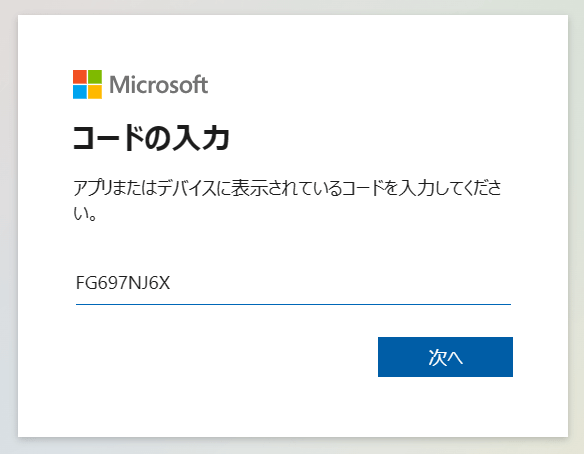
ウイザードの通りに進めると、

azd up環境名をつけるように促されますので適当に付けます。私はこんな感じの名前にしました。
aoa103-searchinternaldocs
サブスクリプションを選ぶように言われますので選び、次はデプロイするシージョンを選択します。East USが無難でしょう。
Azure Portal でのデプロイ状況がわかるリンクが提供されるので、そちらから状況を確認するとよいでしょう。
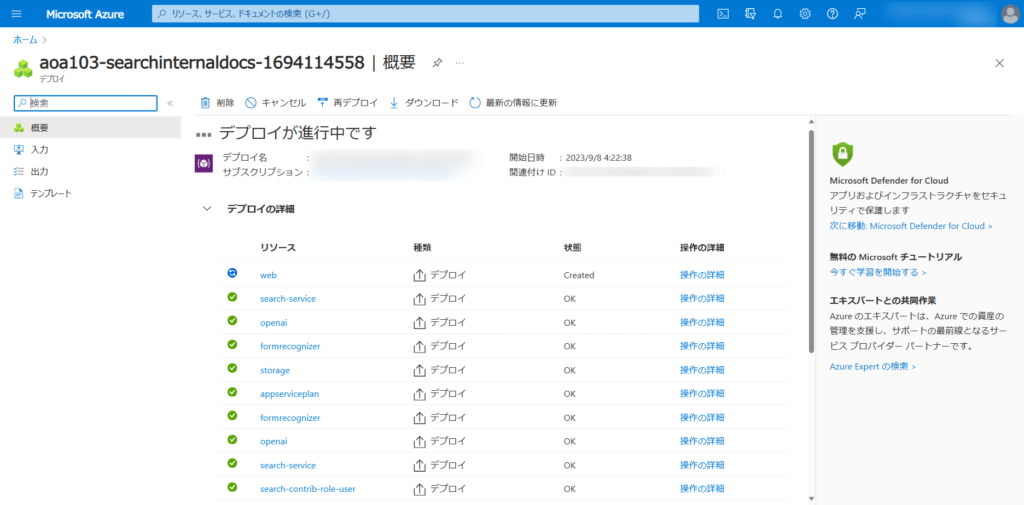
私の場合、15分でデプロイが完了しました。
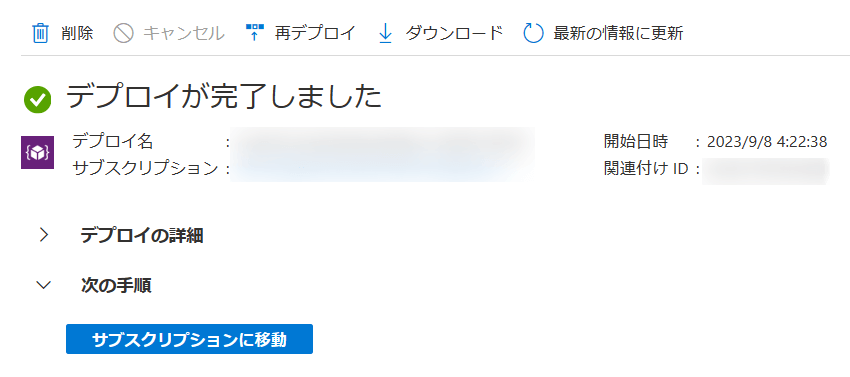
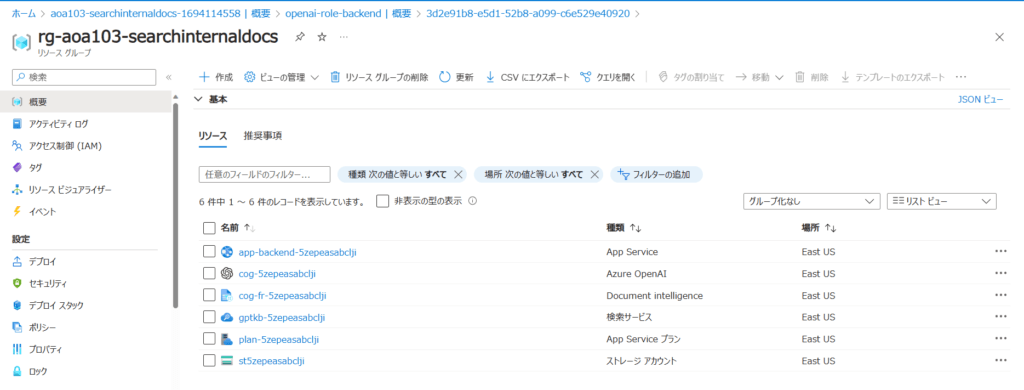
デプロイされたなにかリソースを選択して、その上位のリソースグループに移動します。
6種類のリソースがデプロイされていることがわかります。
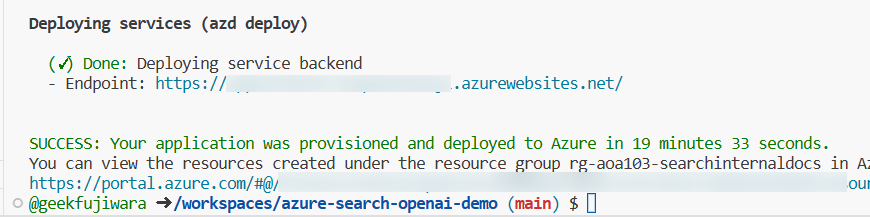
Web アプリへのアクセス
Codespase を確認すると、Endpoint としてWebサイトのURLが生成されています。
アクセスすると以下のようなサイトが立ち上がります。
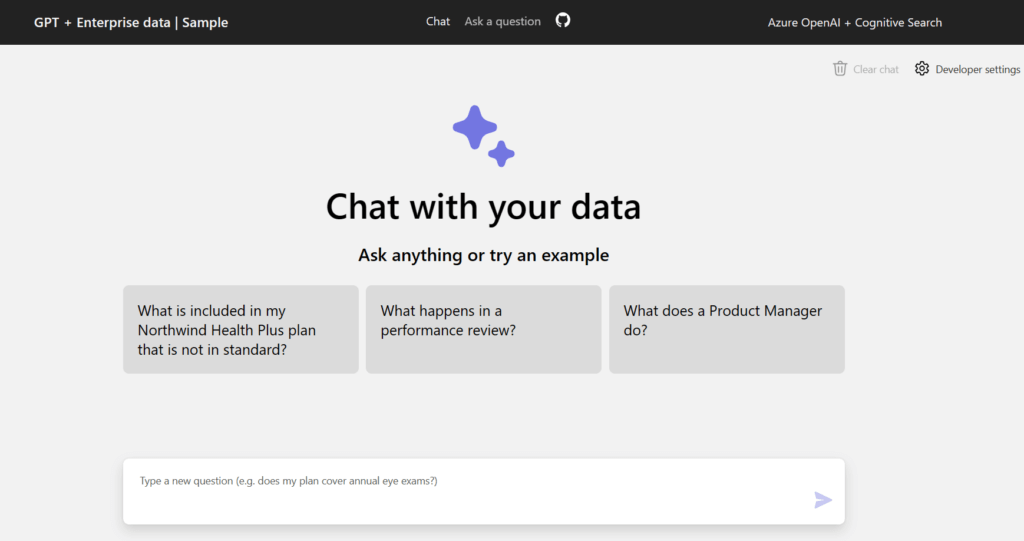
注意事項
このサンプルは、製品アプリケーションのスタート地点として設計されていますが、本番環境への展開前にセキュリティとパフォーマンスを徹底的にレビューする必要があります。以下は考慮すべき事項です。
- OpenAIの容量: デフォルトのTPM(トークン数/分)は30,000に設定されています。これは、1つのユーザーメッセージ/応答あたり1,000トークンを想定して、約30の会話/分に相当します。chatGptDeploymentCapacityとembeddingDeploymentCapacityパラメーターをinfra/main.bicepに変更して、アカウントの最大容量に容量を増やすことができます。また、Azure OpenAI StudioのQuotasタブでどれだけの容量を持っているかを確認することもできます。
- Azure Storage: デフォルトのストレージアカウントはStandard_LRS SKUを使用しています。本番環境では、耐障害性を向上させるために、Standard_ZRSを使用することをお勧めします。infra/main.bicepのstorageモジュールのskuプロパティを使用して指定することができます。
- Azure Cognitive Search: デフォルトの検索サービスは、Standard SKUと無料のセマンティック検索オプションを使用しています。これにより、月間1000件の無料クエリが利用できます。アプリケーションが1000件以上の質問を経験する場合は、semanticSearchを「standard」に変更するか、/app/backend/approachesファイルでセマンティック検索を無効にする必要があります。検索サービスの容量が超過したというエラーが表示される場合は、infra/core/search/search-services.bicepのreplicaCountを変更するか、Azure Portalから手動でスケールアップすると役立つかもしれません。
- Azure App Service: デフォルトのApp Serviceプランは、1つのCPUコアと1.75 GBのRAMを持つBasic SKUを使用しています。1つのCPUコアから始めるPremiumレベルのSKUを使用することをお勧めします。負荷に基づいて自動スケーリングルールやスケジュールされたスケーリングルールを使用し、最大/最小をスケールアップすることができます。
- 認証: デプロイされたアプリはデフォルトで一般公開されています。認証されたユーザーにアクセスを制限することをお勧めします。認証を有効にする方法については、「認証の有効化」を参照してください。
- ネットワーキング: 仮想ネットワーク内に展開することをお勧めします。アプリが企業内部での使用に限定されている場合は、プライベートDNSゾーンを使用してください。また、ファイアウォールやその他の保護手段としてAzure API Management(APIM)を使用することも検討してください。詳細については、「Azure OpenAI Landing Zoneリファレンスアーキテクチャ」を参照してください。
- 負荷テスト: 予想されるユーザー数に対して負荷テストを実行することをお勧めします。このサンプルのlocustfile.pyを使用してlocustツールを使用するか、Azure Load Testingで負荷テストを設定することができます。