
Azure OpenAI Service にドキュメントのインデックスをインプットして回答を生成したい時に、テキストが多すぎることがあります。
そういった際にドキュメントのインデックスの長さを調整する手法として、以下の方法などが考えられます。
- セマンティック検索で該当箇所のみハイライトする
- テキスト分割スキルにてインデックスを分割して保存する
- 事前にドキュメントを分割して保存して、それらにインデックスを作成する
今回はテキスト分割スキルの設定方法を紹介します。その先でAzure OpenAIで利用する方法は以下で紹介しています。
 Azure Cognitive Search でテキスト分割スキルを利用して長いドキュメントから一部だけを抽出してAzure OpenAI にて回答を生成する
Azure Cognitive Search でテキスト分割スキルを利用して長いドキュメントから一部だけを抽出してAzure OpenAI にて回答を生成する
目次
前提条件
- Cognitive Service のFree Tier でも利用可能
- 事前にCognitive Searvice がデプロイ済み
作成方法
新しくスキルセットを作成します。
サンプルコードとしては以下のように設定します。
ソースとしてドキュメントのコンテントを利用して、splitedContent に保管します。
{
"@odata.context": "https://Cognitiveサービス名.search.windows.net/$metadata#skillsets/$entity",
"@odata.etag": "\"0x8DBDB5C2CC86D59\"",
"name": "スキルセット名",
"description": "",
"skills": [
{
"@odata.type": "#Microsoft.Skills.Text.SplitSkill",
"name": "#1",
"description": "",
"context": "/document/content",
"defaultLanguageCode": "ja",
"textSplitMode": "pages",
"maximumPageLength": 1000,
"inputs": [
{
"name": "text",
"source": "/document/content"
}
],
"outputs": [
{
"name": "textItems",
"targetName": "splitedContent"
}
]
}
],
"cognitiveServices": {
"@odata.type": "#Microsoft.Azure.Search.DefaultCognitiveServices",
"description": null
},
"knowledgeStore": null,
"encryptionKey": null
}インデックス フィールドの作成
先に、インデックスに移り、バインド先のフィールドを作成します。
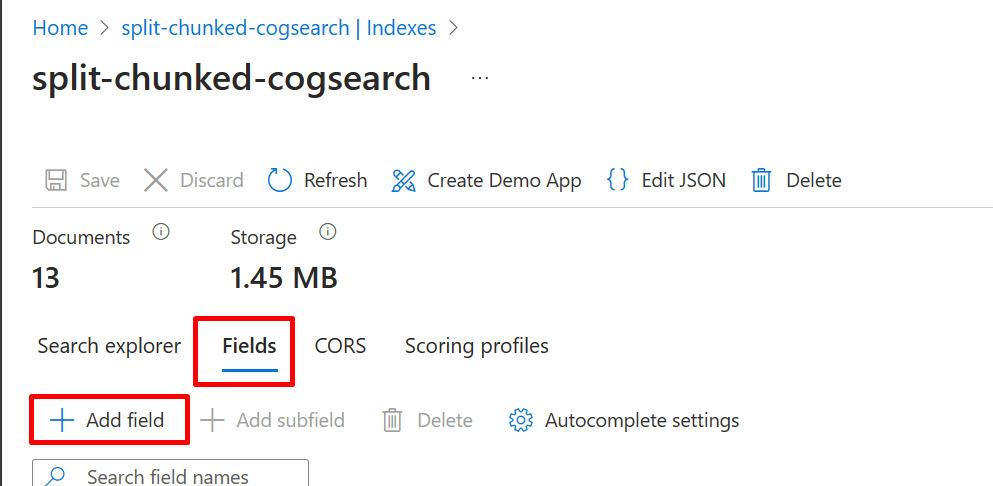
以下のようなフィールド名をつけます。Retrievable、Searchableとします。
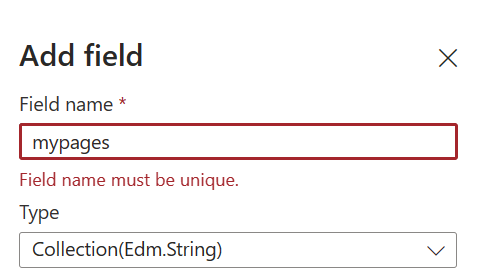
インデックスのフィールドが作成されました。

インデクサーの定義を変更
インデクサーの定義より、先程の mypages フィールドに分割結果をバインドします。
スキルセット名に先程のスキルを追加します。
"skillsetName": "スキルセット名",“outputFieldMappings” に以下を追加します。
"outputFieldMappings": [
{
"sourceFieldName": "/document/content/splitedContent",
"targetFieldName": "mypages"
}
]これにより、mypages というフィールドにバインドされるようになりました。
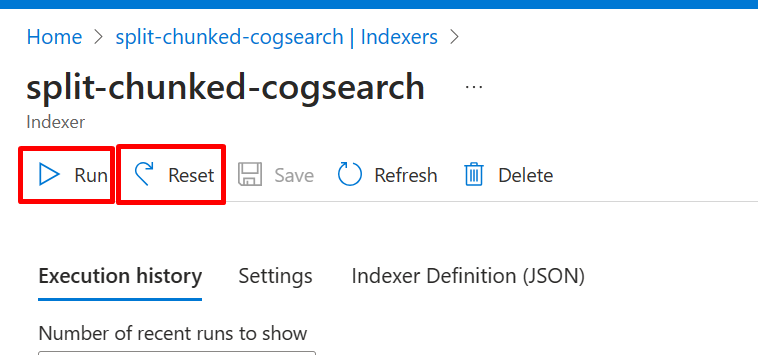
インデックスのリセットと再実行
インデックスをリセットした後、再実行してインデックスを生成します。
この操作はインデクサーから実行します。
リセットを行ってから実行します。
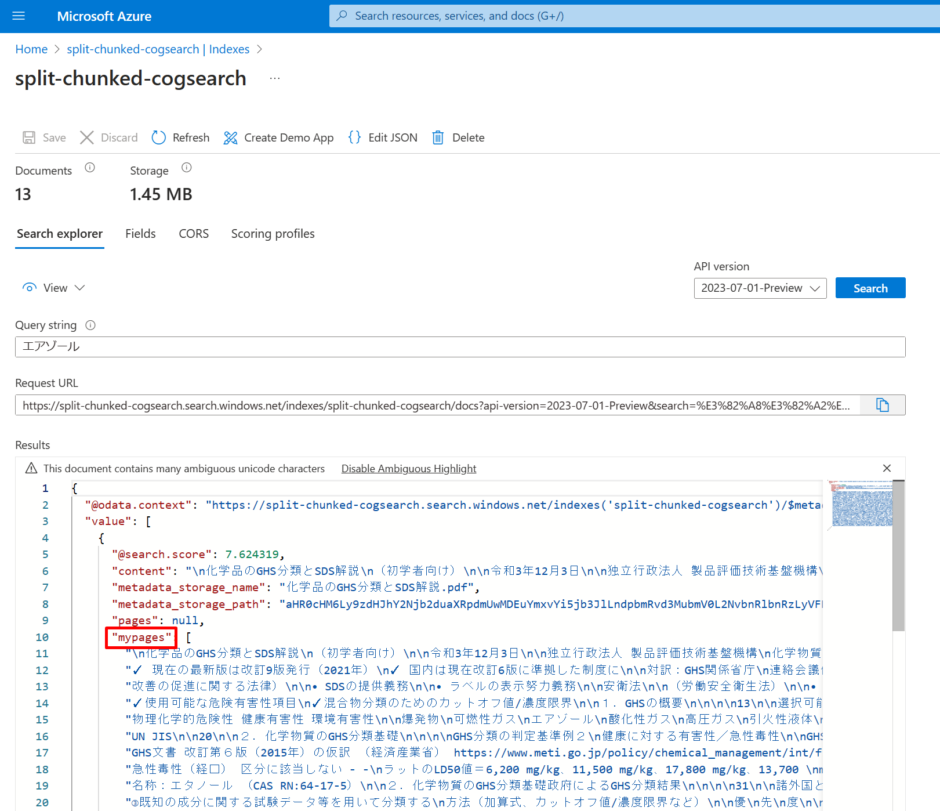
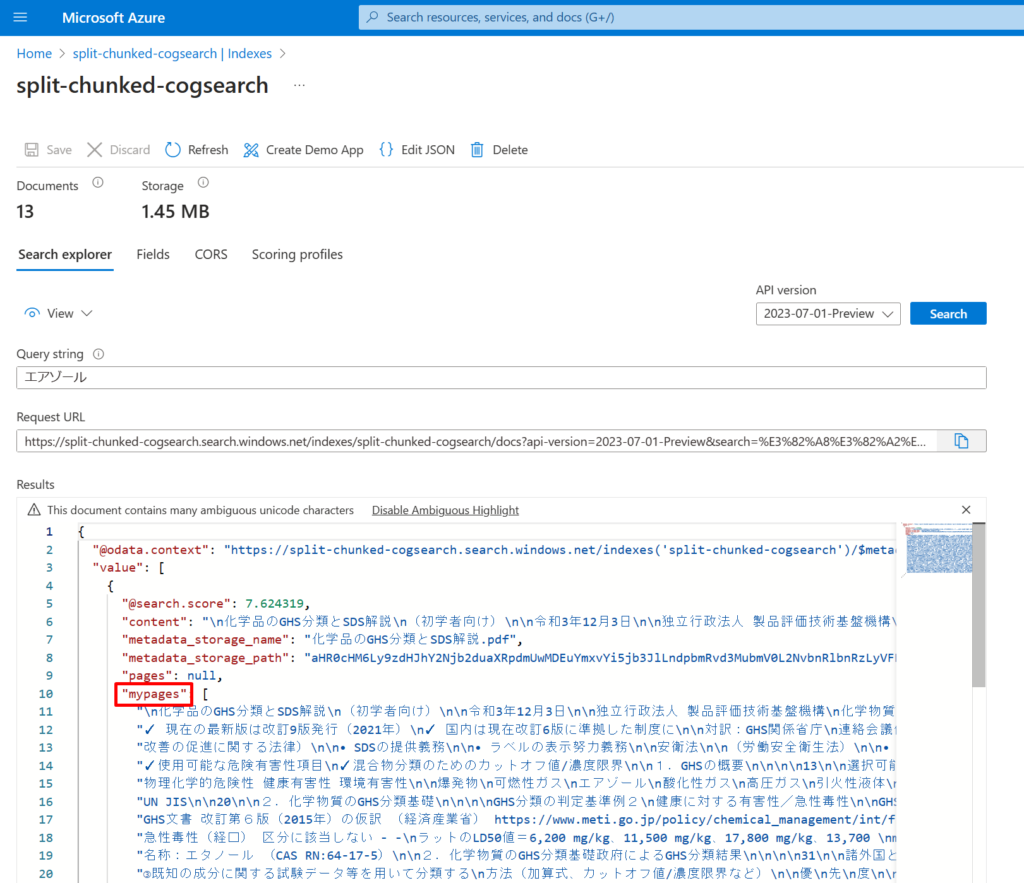
問題なく実行された場合、Search Explorerからmypages というフィールドに検索結果が返ってきます。
トラブルシューティング
フィールドに何も返ってこないという方はインデクサーにてエラーが発生していないか確認してください。
次にこちらのテキスト分割の返答を利用して、Power Automate による関連部分のフィルター処理及びAzure OpenAI による要約を実装します。
Azure Cognitive Search でテキスト分割スキルを利用して長いドキュメントから一部だけを抽出してAzure OpenAI にて回答を生成する